III. Administation
This section covers subsystem management issues, including usage and configuration examples, basic and somewhat specific explanations of how pre-existing scripts have been done.
The Figure 14 repeats earlier picture showing central components of the system.
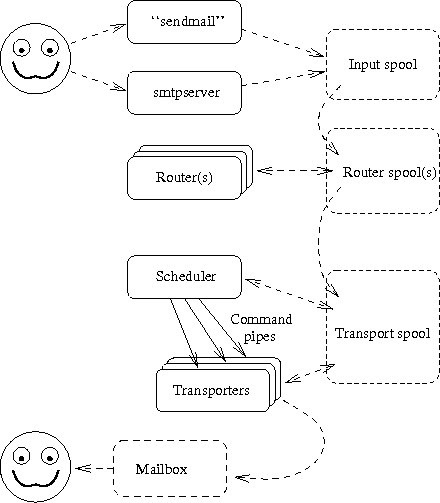
The things in the picture are pointed further here, along with their related auxiliary programs, etc:
- smtpserver
-
Administration of the smtpserver is described at Chapter 12, and detailed Reference is at Chapter 17.
- sendmail
-
The sendmail client compatibility functions program is described at Reference Chapter 18.
- router
-
Administration of the router is at Chapter 13, and Reference is at Chapter 21.
Auxiliary programs used to support the router include:
- zmailer newdb
-
This script has two behaviours, if $
MAILVAR/db/dbases.conf file can be found, utility script newdbprocessor is run. If not, a set of pre-determined individual database regeneration actions is done. - newdb
-
A perl wrapper for actual internal makedb utility taking care of things like correct sequence of file movements after successfull generation of new binary database file(s).
- newaliases
-
Classical aliases database regenerator, subset of zmailer newdb.
- newfqdnaliases
-
Behaves like the newaliases, but processes different database: fqdnaliases. Subset of zmailer newdb.
- scheduler
-
Administration of the scheduler is at Chapter 14, and Reference is at Chapter 22.
Auxiliary programs used to support the scheduler include:
- mailq
-
Utility for querying scheduler's view of the universe.
- mailbox
-
Program driven by the scheduler to do (usually) delivery to local mailboxes, running pipes, and writing to files.
- smtp
-
Program to do delivery to external systems via SMTP protocol (with many supported extensions).
- hold
-
Handler of “hold”-channel deliveries.
- sm
-
There are lots of programs intended to be run under sendmail's M-entry (Mailer-entry) lines. This program supplies that interface layer to an extent which is meaningfull in ZMailer sense.
- errormail
-
Handler of “error”-channel deliveries.
- expirer
-
This is actually driven by the administrator via manual-expirer wrapper script.
- Table of Contents
- 9. DNS and ZMailer
- 10. Security Issues
- 11. The Queue
-
- 11.1. Message Submission Areas
- 11.2. Router Behaviour on Queues
- 11.3. Scheduler, and Transport Agents
- 11.4. Postmaster Analysis Area
- 12. Smtpserver Administration
-
- 12.1. smtpserver.conf
-
- 12.1.1. smtpserver.conf; PARAM keywords
- 12.1.2. smtpserver.conf; “EHLO-style options”
- 12.2. Policy Based Relaying Control
- 12.3. Content Based Filtering
- 13. Router Administration
-
- 13.1. Configuration File Programming Language
- 13.2. Databases
-
- 13.2.1. Using a Pathalias Database With “%0” substitution
- 13.2.2. Mailing Lists and ~/.forward
-
- 13.2.2.1. aliases.cf Logic
- 13.2.2.2. aliases
- 13.2.2.3. Security Considerations
- 14. Scheduler Administration
- 15. Transport Agent Administration
-
- 15.1. Sm Transport Agent
- 16. Logging and Statistics for Administrator
Chapter 9. DNS and ZMailer
The cornerstone of everything in busy Internet email routing is a properly working DNS server, and a modern resolver library. If you use the BIND nameserver, you should be using a recent version. As of this writing (January 2006), BIND server developers recommend version 9. They also strongly recommend, that you do not let zone data masters (either masters, or slave copies) to do any recursive resolving, and do recursive resolvings with servers that do not have locally mastered data.
You can get improved DNS performance by installing local named(8), which does cache replies, including negative replies.
For the file /etc/resolv.conf:
domain your.domain nameserver 127.0.0.1 nameserver (some other server) |
For the local nameserver daemon (named(8)) you should have at least following type of configuration:
For 4.* series: /etc/named.boot
forwarders 10.12.34.56 10.45.67.89
options forward-only
For 8.* series: /etc/named.conf
options {
forward only;
forwarders {
10.12.34.56;
10.45.67.89;
};
};
|
For Solaris, Linux, and some other environments you propably have file /etc/nsswitch.conf. There the interesting line is one referring with “hosts:” tag. In most cases the default setup assumes you will use e.g. NIS(+) in the system overriding DNS and/or local files. In general that is quite bad thing to do — especially for DNS intensive application, like mailers... Suggested value:
hosts: files dns |
At DEC Tru64 there is another file with same purpose as nsswitch.conf, it is: /etc/svc.conf.
At Solaris 2.6 (and after?) there is also a “nscd” daemon (name service cache daemon), which has appeared at times to harm DNS lookup intensive systems. At its configuration file /etc/nscd.conf:
enable-cache hosts no
|
Chapter 10. Security Issues
The intention of the security mechanisms is not to prevent address faking, but to control the privileges which are used to execute pipes, and accessing files (read, and write).
In addition of doing strict privilege control on who can do what, ZMailer has a concept of trust, which shows as a group of accounts who can claim wildly “fradulent” data in their headers.
The trusted accounts are those listed in the ZMailer group or the “trusted” variable in the system configuration (router.cf) file.
Of course when one uses SMTP protocol to inject email, it is extremely easy to “fake” any source and destination envelope and visible addresses.
Having local-parts that allow delivery to arbitrary files, or which can trigger execution of arbitrary programs, can clearly lead to a huge security problem. sendmail does address this problem, but in a restrictive, and unintuitive manner. This aspect of ZMailer security has been designed to allow the privileges expected by common sense.
The responsibility for implementing this kind of security is split between the router, and the transport agent that delivers a message to an address. Since it is the Transport Agent that must enforce the security, it needs some information to guide it. Specifically, for each address it delivers to, some information about the “trustworthiness” of that address is necessary so that the transport agent can determine which privileges it can assume when delivering for that destination. This information is determined by the router, and passed to the transport agent in the message control file. The specific measure of trustworthiness chosen by ZMailer, is simply a numeric user id (uid) value representing the source of the address.
When a message comes into the mailer from an external source, the destination addresses should obviously have no privileges on the local host (when mailing to a file or a program). Similarly, common sense would indicate that locally originated mail should have the same privileges as the originator. Based on an initial user id assigned from such considerations, the privilege attached to each address is modified by the attributes of the various alias files that contain expansions of it. The algorithm to determine the appropriate privilege is to use the user id of the owner of the alias file if and only if that file is not group or world writable, and the directory containing the file is owned by the same user and is likewise neither group nor world writable. If any of these conditions do not hold, an unprivileged user id will be assigned as the privilege level of the address.
It is entirely up to the transport agent whether it will honour the privilege assignment of an address, and indeed in many cases it might not make sense (for example for outbound mail). However, it is strongly recommended that appropriate measures are taken when a transport agent has no control over some action that may affect local files, security, or resources.
The described algorithm is far from perfect. The obvious dangers are:
-
The grandparent directories, to the Nth degree, are ignored, and may not be secure. In that case all security is lost.
-
There is a window of vulnerability between when the permissions are checked, and the delivery is actually made. This is the best argument for embedding the entire local-aliasing into the local-delivery agent program.
There is also another kind of security that must be addressed. That is the mechanism by which the router is told about the origin of a message. This is something that must be possible for the message receiving programs (/bin/rmail and the SMTP server are examples of these) to specify to ZMailer. The router knows of a list of trusted accounts on the system. If a message file is owned by one of these user id's, any sender specification within the message file will be believed by ZMailer. If the message file is not owned by such a trusted account, the router will cross-check the message file owner with any stated “From:” or “Sender:” address in the message header, or any origin specified in the envelope. If a discrepancy is discovered, appropriate action will be taken. This means that there is no way to forge the internal origin of a message without access to a trusted account.
Chapter 11. The Queue
- Table of Contents
- 11.1. Message Submission Areas
- 11.2. Router Behaviour on Queues
- 11.3. Scheduler, and Transport Agents
- 11.4. Postmaster Analysis Area
Normal processing within ZMailer goes via directories described at Figure 11-1. A message may get sidelined or otherwise linked into other directories for several possible reasons.
 |
A filesystem without following three properties is not suitable for
ZMailer's $
Most of the $ However, the $ Adding system reliability in form of having directory data committed to disk at the time of the directory modifying operations returning with success is a nice bonus, although in normal UFS-like cases that taxes system performance heavily. E.g. running fast-and-loose with async metadata updates in Linux EXT2 filesystem gives you performance, but in case the system crashes, your postoffice directory may be in shambles, and important email may have been lost. How exactly you can combat the problem is yours to choose. Most filesystems for UNIX have lots of different options at mount-time, and also by-directory attributes can be set to control these things. Check yours after your decide on what kind of data loss threat you can tolerate at the expence of what speed reduction. (E.g. 300+ day straight uptime with power surges during a thunderstorm at the end of it toasting your machine along with its disks and filesystems, but trouble-free running until then ?) |

There are multiple queues in ZMailer. Messages exist in in one of five locations:
-
Submission temporary directory ($
POSTOFFICE/public/) -
Freezer directory ($
POSTOFFICE/freezer/) -
Router directory ($
POSTOFFICE/router/) -
Deferred directory ($
POSTOFFICE/deferred/) -
Scheduler directories ($
POSTOFFICE/transport/, $POSTOFFICE/queue/)
And sometimes is also copied into the:
-
Postmaster analysis area ($
POSTOFFICE/postman/)
11.1. Message Submission Areas
In few places inside of ZMailer (in parts of router, and more so in parts of scheduler) the system expects the filenames to be decimal encodings of integers of 31 bits (maybe 63 bits at systems with suitably large 'long'), and those integers (modulo something) are used as keys in several internal database lookups.
The numeric values used in filenames must be unique for the entire lifetime of the spool files.
Message submission is done by writing a temporary file into the directory ($POSTOFFICE/public/), the actual format of the submitted message is described in Appendix E.
When the temporary file is completely written, flushed to disk, and closed, it is then renamed into one of the router input directories, usually into $POSTOFFICE/router/ with a name that is a decimal representation of the spool-file i-node number.
This is a way to ensure that the name of the file in the $POSTOFFICE/router/ directory is unique.
The message may also be renamed into alternate router directories, which give lower priorities on which messages to process when.
Sometimes, especially smtpserver built files may be moved into alternate directories. The smtpserver “ETRN” command has two implementations, original
one is by moving the built special file to the directory $POSTOFFICE/transport/ without going through the router. The smtpserver may also move newly arrived files into the $POSTOFFICE/freezer/ directory.
11.2. Router Behaviour on Queues
FIXME:
This description is from era before the router got
“daemonized” in a sense of having separate instance
of queue processor (and it also handles logging/log
rotation) and a worker-farm of routing work processes.
|
FIXME: The system can have multiple router processes running in parallel and competeting on input files. Multiple processes may make sense when there are multiple processors in the system allowing running them in parallel, but also perhaps for handling cases where one process is handling routing of some large list, and other (hopefully) will get less costly jobs.
The router processes have a few different behaviours when they go over their input directories.
First of all, if there are ROUTERDIRS entries, those are scanned for processing after
the primary $POSTOFFICE/router/ directory is found empty.
Within each directory, the router will sort files at first into mod-time order, and then
process the oldest message first. (Unless the router has been started with the “-s” option.)
The router acquires a lock on the message (spool file) by means of renaming the file from its previous name to a name created with formatting statement:
sprintf(buf, "%ld-%d", (long)filestat.st_ino, (int)getpid()); |
Once the router has been able to acquire a new name for the file, it starts off by creating a temporary file of router routing decisions. The file has a name created with formatting statement:
sprintf(buf, "..%ld-%d", (long)filestat.st_ino, (int)getpid()); |
Once the processing has completed successfully, the original input file is moved into the directory $POSTOFFICE/queue/, and the router produced scheduler work-specification file is moved to the $POSTOFFICE/transports/ directory with the same
name that the original file has.
If the routing analysis encountered problems, the message may end up moved into the directory $POSTOFFICE/deferred/, from which the command zmailer
resubmit is needed to return the messages into processing (The router logs should be
consulted for the reason why the message ended up in the /deferred/ area, especially if the
command zmailer resubmit is not able to get the messages processed successfully and the files
end up back in the /deferred/ area.)
If the original message had errors in its RFC-822 compliance, or some other detail, a copy of the message may end up
in the directory $POSTOFFICE/postman/.
See Postmaster Analysis Area on section Section 11.4.
11.3. Scheduler, and Transport Agents
The scheduler work specification files are in the directory $POSTOFFICE/transport/, under which there can be (optionally) one or two levels of subdirectories
into which the actual work files will be scattered to lessen the sizes of individual directories in which files reside,
and thus to speed up the system implied directory lookups at the transport agents, when they open files, (and also in
the scheduler).
When the router has completed message file processing, it places the resulting files into the
top level directory of the scheduler; $POSTOFFICE/transport/, and $POSTOFFICE/queue/.
The scheduler (if so configured by “-H” option) will move the messages into “hashed
subdirectories,” when it finds the new work specification files, and then start processing them.
The transport agents are run with their CWD in directory $POSTOFFICE/transport/, and they open files relative to that location. Actual message bodies, when
needed, are opened with the path prefix “../queue/” to
the work specification file name.
Usually it is the transport agent's duty to log different permanent status reports (failures, successes) into the end of the work-specification file. Sometimes the scheduler also logs something at the end of this file. All such operations are attempted without any sort of explicit locking, instead trusting the write(2) system call to behave in an atomic manner while writing to the disk file, and having a single buffer of data to write.
Once the scheduler has had all message recipient addresses processed by the transport agents, it will handle possible diagnostics on the message, and
finally it will remove the original spool-file from the $POSTOFFICE/queue/, and the work-specification file from $POSTOFFICE/transport/.
11.4. Postmaster Analysis Area
If the filename in the $POSTOFFICE/postman/ directory has an
underscore in it, the reason for the copy is soft, that is, the
message has been sent through successfully in spite of being copied into the directory.
If the filename in that directory does not have an underscrore in it, that file has not been processed successfully, and the only copy of the message is now in that directory!
Usually forementioned underscoreless filenames are double-errors, that is, error messages to error messages. There is nowhere else to send them.
The indication of error message is, of course, MAIL FROM:<> per RFC 821.
If the smtpserver receives a message with content that the policy filtering system decides to be dubious, it can move the message into $POSTOFFICE/freezer/ directory with a bit explanatory name of type:
sprintf(buf, "%ld.%s", (long)filestat.st_ino, causecodestring); |
The files in the freezer-area are in the input format to the router, and as of this writing, there are no tools to automatically process them for obvious spams, and leave just those that were falsely triggered.
Chapter 12. Smtpserver Administration
- Table of Contents
- 12.1. smtpserver.conf
-
- 12.1.1. smtpserver.conf; PARAM keywords
- 12.1.2. smtpserver.conf; “EHLO-style options”
- 12.2. Policy Based Relaying Control
- 12.3. Content Based Filtering
Things to place here - administrative stuff - runtime command-line parameters (most important of them) - smtpserver.conf - PARAM entries (most common/important ones) - SMTP policy-control - content-policy interface |
The smtpserver is ZMailer's component to receive incoming email via SMTP protocol. Be it thru TCP channel, or thru Batch-SMTP.
The Figure 12-1 repeats earlier picture showing central components of the system, and where the smtpserver is in relation to them all.

The smtpserver program actually has several operational modes.
-
It can operate as a stand-alone internet service socket listener, which forks off childs that do the actual SMTP-protocol service.
-
It can be started from under the control of the inetd(8) server, and it can there fulfill most of the the same roles as it does in the stand-alone mode.
-
It can even be used to accept Batch-SMTP from incoming files (UUCP, and BITNET uses, for example).
The runtime command-line options are as follows:
smtpserver [-46aignvBV] [-p port] [-l logfile] [-s ] [-s [ftveR]]'strict'
[-L maxloadaver] [-M SMTPmaxsize] [-P postoffice] [-R router]
[-C cfgfile] [-T IPv4/IPv6-address-literal]
The most commonly used command line options are:
smtpserver [-aBivn] [-s ehlo-styles] [-l logfile] [-C cfgpath]
Without any arguments the smtpserver will start as a daemon listening on TCP port 25 (SMTP).
Most important of the options are:
-a-
Query IDENT information about the incoming connection. This information (if available at all) may, or may not tell who is forming a connection.
-B-
The session is Batch-SMTP a.k.a. BSMTP type of session. Use of “
-i” option is needed, when feeding the input batch file. -i-
This is interactive session. I/O is done thru stdin/stdout.
-v-
Verbose trace written to stdout for use in conjunktion with “
-i”, and “-B”. -n-
This tells that the smtpserver is running under inetd(8), and that the stdin/stdout file handles are actually network sockets on which we can do peer identity lookups, for example.
-s ehlo-style-
Default value for various checks done at SMTP protocol MAIL FROM, RCPT TO, VRFY, and EXPN commands. These are overridden with the value from EHLO-patterns, if they are available (more below)
-s 'strict'-
Special value directing the system to be extremely picky about the incoming SMTP protocol — mainly for protocol compliance testing, usually way too picky for average (sloppy) applications out there...
-l logfilepath-
Filename for the smtpserver input protocol log. This logs about everything, except actual message data...
-l 'SYSLOG'-
This tells smtpserver that it shall send all incoming smtp protocol transactions via
syslogfacility to elsewere. Used syslog parameters are: FACILITY=mail, LEVEL=debug.This option may be used in addition to the preceding file logging variant. Double-use of file referring variant uses the last defined file, but this doesn't affect files at all.
-C configfilepath-
Full path for the smtpserver configuration in case the default location can not be used for some reason.
-M SMTPmaxsize-
SMTPmaxsize defines the absolute maximum size we accept for incoming email. (Default: infinite) (This is a local policy issue.)
-T [IPv4-or-IPv6-address-literal]-
An address literal is used in interactive test mode to check how the rules work with given inputs when the source address of the connection is what is given in headers.
12.1. smtpserver.conf
If the system has file $MAILSHARE/smtpserver.conf (by
default), that file is read for various parameters, which can override most of those possibly issued at the command
line.
Example configuration is is in figure Figure 12-2.
Figure 12-2. Sample smtpserver.conf file
#PARAM maxsize 10000000 # Same as -M -option #PARAM max-error-recipients 3 # More than this is propably SPAM! #PARAM MaxSameIpSource 10 # Max simultaneous connections from # # any IP source address #PARAM ListenQueueSize 10 # listen(2) parameter # # Enables of some commands: #PARAM DEBUGcmd #PARAM EXPNcmd #PARAM VRFYcmd #PARAM enable-router # This is a security decission for you. # # This is needed for EXPN/VRFY and interactive # # processing of MAIL FROM and RCPT TO addresses. # # However it also may allow external user entrance # # to ZMailer router shell environment with suitably # # pervert input, if quotation rules are broken in # # the scripts. PARAM help ------------------------------------------------------------- PARAM help This mail-server is at Yoyodyne Propulsion Inc. PARAM help Our telephone number is: +1-234-567-8900, and .... PARAM help ------------------------------------------------------------- # The policy database: (NOTE: See 'makedb' for its default suffixes!) PARAM policydb $DBTYPE $MAILVAR/db/smtp-policy # External program for received message content analysis: #PARAM contentfilter $MAILBIN/smtp-contentfilter .... # # TLSv1/SSLv[23] parameters; all must be used for the system to work! # # See doc/guides/openssl, or: # http://www.aet.tu-cottbus.de/personen/jaenicke/pfixtls/doc/setup.html # #PARAM use-tls #PARAM tls-CAfile $MAILVAR/db/smtpserver-CAcert.pem #PARAM tls-cert-file $MAILVAR/db/smtpserver-cert.pem #PARAM tls-key-file $MAILVAR/db/smtpserver-key.pe .... # # HELO/EHLO-pattern style-flags # [max loadavg] # localhost 999 ftveR some.host.domain 999 !NO EMAIL ACCEPTED FROM YOUR MACHINE # If the host presents itself as: HELO [1.2.3.4], be lenient to it.. # The syntax below is due to these patterns being SH-GLOB patterns, # where brackets are special characters. \[*\] 999 ve # Per default demant strict syntactic adherence, including fully # qualified addresses for MAIL FROM, and RCPT TO. To be lenient # on that detail, remove the "R" from "veR" string below: * 999 veR |
12.1.1. smtpserver.conf; PARAM keywords
The PARAM keywords and values are:
maxsizenn-
Maximum size in the number of bytes of the entire spool message containing both the transport envelope, and the actual message. That is, if the max-size is too low, and there are a lot of addresses, the message may entirely become undeliverable..
max-error-recipientsnn-
In case the message envelope is an error envelope (MAIL FROM:<>), the don't accept more than this many separate recipient addresses for it. The default value is 3, which should be enough for most cases. (Some SPAMs claim to be error messages, and then provide a huge number of recipient addresses...)
MaxSameIpSourcenn-
(Effective only on daemon-mode server — not on “
-i”, nor “-n” modes.) Sometimes some systems set up multiple parallel connections to same host (qmail ones especially, not that ZMailer has entirely clean papers on this - at least up to 2.99.X series), we won't accept more than this many connections from the same IP source address open in parallel. The default value for this limit is 10. ListenQueueSizenn-
This relates to newer systems where the
listen(2) system call can define higher limits, than the traditional/original 5. This limit tells how many nascent TCP streams we can have in SYN_RCVD state before we stop answering to incoming SYN packets requesting opening of a connection.There are entirely deliberate denial-of-service attacks based on flooding to some server many SYNS on which it can't send replies back (because the target machines don't have network connectivity, for example), and thus filling the back-queue of nascent sockets. This can also happen accidentally, as the connectivity in between the client host, and the server host may have a black hole into which the SYN-ACK packets disappear, and the client thus will not be able to get the TCP startup three-way handshake completed.
Most modern systems can have this value upped to thousands to improve systems resiliency against malicious attacks, and most likely to provide complete immunity against the accidental “attack” by the failing network routing.
DEBUGcmd-
FIXME! WRITEME! #PARAM DEBUGcmd
EXPNcmd-
FIXME! WRITEME! #PARAM EXPNcmd
VRFYcmd-
FIXME! WRITEME! #PARAM VRFYcmd
enable-router-
FIXME! WRITEME! #PARAM enable-router # This is a security decission for you.
help'string'-
This one adds yet another string (no quotes are used) into those that are presented to the client when it asks for “HELP” in the SMTP session.
PolicyDBdbtype dbpath-
This defines the database type, and file path prefix to the binary database containing policy processing information. More of this below. Actual binary database file names are formed by appending type specific suffixes to the path prefix. For example NDBM database appends “.pag” and “.dir”, while BSD-Btree appends only “.db”. (And the latter has only one file, while the first has two.)
For an operative overview, see Section 12.2, and for deeper details, see Section 17.4.
contentfilterprogrampath-
The contentfilter studies the received message at the end of the DATA or BDAT transaction, and produces syncronous report about should be message be accepted or not. Unlike the
PolicyDB, this does not (should not) care about validity of envelope source and recipient address validities, although perhaps it should consider at least the recipients in some cases -- e.g. accept about anything when the destination is <postmaster>.For an operative overview, see Section 12.3, and for deeper details, see Section 17.5.
12.1.2. smtpserver.conf; “EHLO-style options”
All lines that are not comments, nor start with uppercase keyword “POLICY” are “EHLO-style patterns”. This is the oldest form of configuring the smtpserver, and as such, it can be seen...
Behaviour is based on glob patterns matching the HELO/EHLO name given by a remote client. Lines beginning with a “#”, or whitespace are ignored in the file, and all other lines must consist of two tokens: a shell-style (glob) pattern starting at the beginning of the line, whitespace, and a sequence of style flags. The first matching line is used. As a special case, the flags section may start with a ! character in which case the remainder of the line is a failure comment message to print at the client. This configuration capability is intended as a way to control misbehaving client software or mailers.
The meanings of the style flag characters are as follow:
f-
Check “MAIL FROM” addresses through online processing at the attached router process
t-
Check RCPT TO addresses through online processing at the attached router process
v-
Allow execution of VRFY command online at the attached router process
e-
Allow execution EXPN command online at the attached router process
R-
Require addresses to be in fully qualified (domained) form: “local@remote” (strict 821)
S-
Allow Sloppy input for systems incapable to respect RFC 821 properly; WinCE1.0 does: “MAIL FROM:user@domain” :-(
12.2. Policy Based Relaying Control
The policy database that smtpserver uses is built with policy-builder.sh script, which bundles together a set of policy source files:
| File | What |
|---|---|
| DB/smtp-policy.src | The boilerplate |
| DB/localnames | (“= _localnames”) |
| DB/smtp-policy.relay.manual | (“= _full_rights”) |
| DB/smtp-policy.relay | (“= _full_rights”) |
| DB/smtp-policy.mx.manual | (“= _relaytarget”) |
| DB/smtp-policy.mx | (“= _relaytarget”) |
| DB/smtp-policy.spam.manual | (“= _bulk_mail”) |
| DB/smtp-policy.spam | (“= _bulk_mail”) |
If you want, you can modify your smtp-policy.src boilerplate file as well as your installed policy-builder.sh script.
Basically these various source files (if they exist) are used to combine knowledge of valid users around us:
- smtp-policy.src
-
The controlling boilerplate, which you should modify!
- localnames
-
Who we are — ok domains for receiving.
- smtp-policy.relay
-
Who can use us as outbound relay.
Use [ip.number]/maskwidth here for listing those senders (networks) we want to trust. You may also use domains, or domain suffixes so that the IP-reversed hostnames are accepted (but that is a it risky thing due to ease of fakeing the reversed domain names):
[11.22.33.00]/24 ip-reversed.host.name .domain.suffix
Server sets its internal “always_accept” flag at the source IP address tests before it decides on what to tell to the contacting client. The flag is not modified afterwards during the session.
Usage of domain names here is discouraged as there is no way to tell that domain “foo.bar” here has different meaning than same domain elsewere — at “smtp-policy.mx,” for example.
- smtp-policy.mx.manual, smtp-policy.mx
-
Who really are our MX clients. Use this when you really know them, and don't want just to trust that if recipient has MX to you, it would be ok…
You can substitute this knowledge with a fuzzy feeling by using “acceptifmx -” attribute at the generic boilerplate. List here domain names, possibly suffixes:
The suffix (“.mx-target.dom”) does not match to the “dot-less” domain name: “mx-target.com” !mx-target.dom .mx-target.dom
You CAN also list here all POSTMASTER addresses you accept email routed to:
these are magic addresses that email is accepted to, even when everything else is blocked.postmaster@local.domain postmaster@client.domain
- smtp-policy.spam.manual, smtp-policy.spam
-
Those users, and domains that are absolutely no-no for senders, or recipients no matter what earlier analysis has shown. (Except for those senders that we absolutely trust..)
user@domain user@ domain
At the “smtp-policy.src” boiler-plate file there is one particular section containing default setting statements. See figure Figure 12-3 for the salient details concerning this.
Figure 12-3. The smtp-policy.src file default settings fragment
...
#| ===========================
#|
#| Default handling boilerplates:
#|
#| "We are not relaying between off-site hosts, except when ..."
#|
#| You MUST uncomment one of these default-defining pairs, or the blocking
#| of relay hijack will not work at all !
#|
#| == 1st alternate: No MX target usage, no DNS existence verify
#| Will accept for reception only those domains explicitely listed
#| in ``smtp-policy.mx'' and ``localnames'' files. Will not do
#| verifications on validity/invalidity of source domains:<foo@bar>
#
# . relaycustomer - relaytarget -
# [0.0.0.0]/0 relaycustomer - relaytarget -
#
#| == 2nd alternate: No MX target usage, DNS existence verify
#| Like the 1st alternate, except will verify the sender
#| (MAIL FROM:<..>) address for existence of the DNS MX and/or
#| A/AAAA data -- e.g. validity.
#| If RBL parameters are set below, will use them.
#
# . relaycustomer - relaytarget - senderokwithdns + = _rbl1
# [0.0.0.0]/0 relaycustomer - relaytarget - senderokwithdns + = _rbl0
#
#| == 3rd alternate: MX relay trust, DNS existence verify
#| For the people who are in deep s*... That is, those who for some
#| reason have given open permissions for people to use their server
#| as MX backup for their clients, but don't know all domains valid
#| to go thru... Substitutes accurate data to user's whimsical DNS
#| maintenance activities. Vulnerable to inbound MX resource abuse.
#| If RBL parameters are set below, will use them.
. relaycustomer - acceptifmx - senderokwithdns + = _rbl1
[0.0.0.0]/0 relaycustomer - acceptifmx - senderokwithdns + = _rbl0
#| == 4th alternate: Sender & recipient DNS existence verify
#| This is more of an example for the symmetry's sake, verifies that
#| the source and destination domains are DNS resolvable, but does not
#| block relaying
#
# . senderokwithdns - acceptifdns -
# [0.0.0.0]/0 senderokwithdns - acceptifdns -
#
#|
#| You may also add ``test-dns-rbl +'' attribute pair to [0.0.0.0]/0
#| of your choice to use Paul Vixie's http://maps.vix.com/ MAPS RBL
#| system.
#|
#| These rules mean that locally accepted hostnames MUST be listed in
#| the database with ``relaytarget +'' attribute.
#|
#| ===========================
#|
#| RBL type test rules:
#| First RBL variant: NONE OF THE RBL TESTS
_rbl0 # Nothing at early phase
_rbl1 # Nothing at late phase
#| Second RBL variant: Early block with RBL+DUL+RSS
#_rbl0 test-dns-rbl +:dul.maps.vix.com:relays.mail-abuse.org
#_rbl1 # Nothing at late phase
#| Third RBL variant: Late block with RBL+DUL+RSS
#_rbl0 rcpt-dns-rbl +:dul.maps.vix.com:relays.mail-abuse.org
#_rbl1 test-rcpt-dns-rbl +
#| (The "+" at the DNS zone defines is treated as shorthand to
#| "rbl.maps.vix.com")
#|
#| The Third RBL variant means that all target domains can all by
#| themselves choose if they use RBL to do source filtering.
#| The ``= _RBL1'' test *must* be added to all domain instances
#| where the check is wanted.
#| (Including the last-resort domain default of ".")
#| (Or inverting: If some recipient domain is *not* wanting RBL-type
#| tests, that domain shall have ``test-rcpt-dns-rbl -'' attribute
#| pair given for it at the input datasets - consider smtp-policy.mx
#| file!)
#|
#| These rules mean that locally accepted hostnames MUST be listed in
#| the database with 'relaytarget +' attribute. ("acceptifmx *" allows
#| reception if the local system is amonst the MXes.)
#|
#| ===========================
#|
#| If your system has ``whoson'' server (see contrib/whoson-*.tgz),
#| you can activate it by adding 'trust-whoson +' attribute pair to
#| the wild-card IP address test: [0.0.0.0]/0 of your choise.
#|
#| ===========================
#|
#| For outbound relaying control for fixed IP address networks, see
#| comments in file: smtp-policy.relay
#|
#| ===========================
...
|
12.3. Content Based Filtering
The ZMailer can do also message content analysis with an external program at the end of DATA-dot phase, and BDAT LAST phase (that is, when the input message is complete, and final acknowledgement is expected by the email sender.)
The program becomes active if PARAM entry “contentfilter” is set:
# External program for received message content analysis: #PARAM contentfilter $MAILBIN/smtp-contentfilter |
More details are at the Reference part: Section 17.5.
Chapter 13. Router Administration
- Table of Contents
- 13.1. Configuration File Programming Language
- 13.2. Databases
-
- 13.2.1. Using a Pathalias Database With “%0” substitution
- 13.2.2. Mailing Lists and ~/.forward
-
- 13.2.2.1. aliases.cf Logic
- 13.2.2.2. aliases
- 13.2.2.3. Security Considerations
The router is the part of the ZMailer that uses algorithms, and control databases to determine what latter stages, like scheduler should do to the message.
The Figure 13-1 repeats earlier picture showing central components of the system, and where the router is in relation to to all.
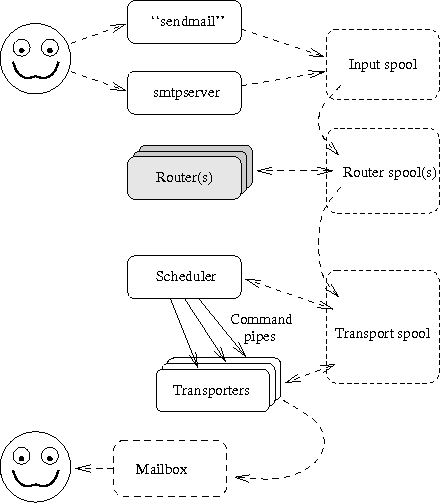
In following our intention is to cover topics of:
-
What input data router uses
-
What output it produces
-
How the router is configured, including of what is 'dbases.conf' file.
-
How it can be tuned
FIXME:
- Intro to what the router does to the message
- How the configuration scripts are loaded
- How the standard scripts are tunable by means of databases,
specifically 'dbases.conf'
- The ROUGHT logic of the standard scripts
- What to do if one wants to tune ?
|
The names (determined at compile-time) and interface specifications for the routing and crossbar functions, are the only crucial “magical” things one needs to contend with in a proper router configuration. The syntax and semantics of the configuration file's contents are dealt with in the following subsection. The details of the two functions introduced here are specified after that, once the necessary background information has been given.
Router behavior is controlled by a configuration file read at startup. It is a zmsh(1) script that uses facilities provided built into the router.
The configuration file looks like a Bourne Shell script at first glance. There are minor syntax changes from standard sh(1), but the aim is to be as close to the Bourne Shell language as is practical. In fact some aspects of variable handling are more of PERL style, and others are even LISPish.
The contents of the file are compiled into bytecode, which can then be interpreted by the router. The configuration file is usually self-contained, although an easy mechanism exists to make use of external UNIX programs when so desired. Together with a very flexible database lookup mechanism, functions, and address manipulation based on token-matching regular expressions, the configuration file language is an extremely flexible substrate to accomplish its purpose. When the language is inadequate, or if speed becomes an issue, it is possible to call built in (C coded) functions. The interface to these functions is mostly identical to what a standalone program would expect (modulo symbol name clashes and return values), to ease migration of external programs to inclusion in the router process.
13.1. Configuration File Programming Language
Whenever the router process starts, its first action is to read its configuration file. The
configuration file is a text file which contains statements interpreted immediately when the file is read. Some
statements are functions, in which case the function is defined at that point in reading the configuration file. The
purpose of the configuration file is to provide a simple way to customize the behavior of routing process of the
mailer, and this is primarily achieved by defining the router (at Section
21.4.2), and crossbar (at Section 21.4.3) functions.
For these to work properly, some initialization code and auxiliary functions will usually be needed.
At first sight, a configuration file looks like a Bourne shell script. The ideal is to duplicate the functionality, syntax, and to a large degree the semantics, of a shell script. Therefore, the configuration file programming language is defined in terms of its deviation from standard Bourne shell syntax and semantics. The present differences are:
-
No
repeatstatement. -
Functions are allowed, parameter lists are allowed. If not enough arguments are present in a function call to exhaust the parameter list, the so-far unbound parameter variables are bound to "" (the empty string) as local variables. For example, this is the identity address rewriting function:
null (address) { return $address # surprise! }
-
Multiple-value returns are allowed. The
returnstatement can be used to return a non-“” (non-empty string) value from a function. The following are all legalreturnstatements:return return $address return $channel ${next_host} ${next_address}
-
Variables are dynamically scoped, local variables are the ones in a function's parameter list and those declared with the “
local” statement. Only the first value of a multiple-value return may be assigned to a variable. All values are either strings, or lists, so no type information, checking, or declaration, is necessary. -
Quoting is a bit stilted. All quotes (double-, single-, back-), must appear in matching pairs at the beginning and at the end of a word.
{\bf\large CHECK!} Single quotes are not stripped, double quotes cause the enclosed character sequence to be collected into a quoted-string RFC822 token.
For example, the statement:
is evaluated asfoo `bar "`baz`"`
(apply 'foo (apply 'bar (baz)))
-
In standard shells the
IFSguides on how variable expansion results are to be treated. Namely in cases where the expansion happens without being enclosed into double-quotes, the expansion result is at first split withIFScontained characters forming the separation sequences.ZMailer's “shell” behaves alike PERL in this regard, and will not do
IFSinterpolation on the result. However, unlike with PERL, double-quoted evaluation will not have its contents re-evaluated.Thus it is equally safe to do assignments like:
var1='some text here' var2=' more text cat1="$var1$var2" cat2=$var1$var2
The notable thing at this particular example is that both result variables are catenates of the input strings.
However! If either of inputs is a list of any kind, then the catenate is not to be done this way! See
lappend. -
Due to lack of implicite split by the
IFScharacters, ZMailer “shell” contains functionifssplit. -
The
forconstruct is even more strange, and classical Bourne script:countvar='1 2 3 4 5 6' for x in $countvar; do ... ; done
Yields only nasty surprise.
Here are two alternates on how to do it:
countvar='1 2 3 4 5 6' for x in $(ifssplit $countvar); do ... ; done countvar=(1 2 3 4 5 6) for x in $(elements $countvar); do ... ; done
-
Conditional substitution forms are supported:
But appear to be borken ??${variable:=value} ${variable:-value} ${variable:+value}
-
Patterns (in case labels) are parsed once, the first time they are encountered.
This is like with PERL's “m/../o” patterns.
-
At the end of a case label, the sequentially next case labels of the same case statement will be tried for successful pattern matching (and the corresponding case label body executed). The only exceptions (apart from encountering a return statement) are:
again-
a function which retries the current case label for a match
break-
continues execution after the current case statement
-
A regular expressions using variant of “
case”, with two flavours:ssift-
A “String Shift” where the input string is handled as is.
tsift-
A “Token Shift” where the input string is spliced according to RFC-822 tokenization rules. Especially RFC-822 special characters cause tokens to split.
With “
tsift” the “.” (dot) will match any single “rfc822-token”, that is, input string “foo.bar” has three tokens: “foo” (atom), “.” (dot, special), and “bar” (atom).
Overall usage of these “
sifts” is very much like that of “case”, including the need for matching termination tokens:ssift "$invar" in pattern statements ;; tfiss tsift "$invar" in pattern statements ;; tfist
-
Various standard Bourne shell functions do not exist built in.
-
The general form of function calls in the system is:
$(funcname arguments)
It returns a scalar or list object, and the result can be stored into variables at will.
-
Relations, and other database lookups are constructed as function calls where the relation name is the function name. More about this later.
There are currently only three entry points (i.e. magic names known to the router code) in
the configuration scripts, namely the process, the router,
and the crossbar -functions.
-
The
process()script function is called with a file name as argument. The file is typically located in the $POSTOFFICE/router/ directory. Theprocess()is a protocol switch function which uses the form of the file name to determine how to process different types of messages. -
The
router()script function is called with an address as argument, and returns a quad of (channel, host, user, attribs) as three separate values, corresponding to the channel the message should be sent out on (or, therouterfunction can also be called to check on who sent a message), the host or node name for that channel (semantics depend per what channel is in effect), and the address the receiving agent should transmit to. The fourth parameter is “attribute” storage variable name from which a “privilege” value-pair is picked for recipient address security control functions. -
The
crossbar()function is in charge of rewriting envelope addresses, selecting message header address munging type (a function to be called with each message header address), and possibly doing per-message logging or enforcing restrictions deemed necessary. It takes a sender-quad and a receiver-quad as arguments (eight parameters altogether). It returns the new values for each element of the two quads, and in addition a function name corresponding to the function to be used to rewrite header addresses for the specific destination. If the destination is to be ignored, returning a null function name will accomplish this.
There is a fourth script entrypoint used by the smtpserver program, namely the server(), which is used to implement smtpserver's realtime support facilities for “EXPN”, and “VRFY” commands, and optionally also to process addresses in “MAIL FROM:<…>”, and “RCPT TO:<…>” commands.
The router has several built in (C coded) functions. Their calling sequence and interface specification is exactly the same as for the functions defined in the configuration file. Some of these functions have special semantics, and they fall into three classes, as follows:
-
Functions that are critical to the proper functioning of the configuration file interpreter:
return-
returns its argument(s) as the value of a function call
again-
repeats the current
case, and*siftlabel break-
exits
case, and*siftstatements
-
Functions that are necessary to complete the capabilities of the interpreter:
relation-
defines a database to the database lookup mechanism
sh-
an internal function which runs its arguments as /bin/sh would
-
Non-critical but recommended functions:
echo-
emulates /bin/echo
exit-
aborts the router with the specified status code
hostname-
internal function to get and set the local idea about the system name
trace-
turns on selected debugging output
untrace-
turns off selected debugging output
[,test-
emulates a subset of “/bin/test” (a.k.a. “/bin/[”) functionality.
The relation
function is described in “Databases”, at section Section
13.2. Functions trace, and untrace are described in connection with debugging.
See Logging and Statistics, section Chapter 16. (This will probably change to Reference/Router/Debugging)
The hostname
function requires some further explanation. It is intended to emulate the BSD UNIX /bin/hostname
functionality, except that setting the hostname will only set the router's idea of the hostname,
not the system's. Doing so will enable generation of “Message-Id:” and “Received:” “trace” headers on all messages
processed by the router.
It is done this way since the router needs to know the official domain name of the local host in order to properly generate these headers, and this method is cleaner than reserving a magic variable for the purpose.
The router cannot assume the hostname reported by the system is a properly qualified domain name, so the configuration file may generate it using whichever method it chooses.
If the hostname indeed is a fully qualified domain name, then:
hostname "hostname" |
Finally, note that a symbol can have both a function-value and a string-value. The string value is of course accessed using the “$” prefix convention of the Bourne shell language.
To test the configuration or routing data, proceed as shown in figure Figure 13-2.
Figure 13-2. Example of running tests on router
sh$ $MAILBIN/router -i (select interactive mode) z$ rtrace (turn tracing on) z$ router user@broken.address (the address that gave you trouble) z$ router another@address (and so on) |
Old salts can use “/usr/lib/sendmail -bt” instead of “router -i”. Once satisfied that routing works, command:
zmailer router |
You can also run the router directly on a message. Copy your message to someplace other than the postoffice (/tmp/ is usually good), to a numeric file name. If the file name is “123”, you run
$MAILBIN/router 123 |
13.2. Databases
FIXME:
- Intro
- How 'dbases.conf' file works
- How the databases are defined in the deep down inside ('relation' function)
- How lookup works
|
Many of the decisions and actions taken by configuration file code depend on the specifics of the environment the MTA finds itself in. So, not just the facts that the local host is attached to (say) the UUCP network and a Local Area Network are important, but it is also essential to know the specific hosts that are reachable by this method. Hardcoding large amounts of such information into the configuration file is not practical. It is also undesirable to change what is really a program (the configuration file), when the information (the data) changes.
The desirable solution to this data abstraction problem is to provide a way for the configuration file programmer to manage such information externally to ZMailer, and access it from within the router. The logical way to do this is to have an interface to externally maintained databases. These databases need not be terribly complicated; after all the simplest kind of information needed is that a string is a member of some collection. This could simply correspond to finding that string as a word in a list of words.
However, there are many ways to organize databases, and the necessary interfaces cannot be known in advance. The router therefore implements a framework that allows flexible interfacing to databases, and easy extension to cover new types of databases.
To use a database, two things are needed: the name of the database, and a way of retrieving the data associated with a particular key from that database. In addition to this knowledge, the needs of an MTA do include some special processing pertinent to its activities and the kind of keys to be looked up.
Specifically, the result of the data lookup can take different forms: one may be interested only in the existence of
a datum, not its value, or one may be looking up paths in a pathalias database and need to substitute the proper thing in place of “%s” in the string returned from the database lookup. It
should be possible to specify that this kind of postprocessing should be carried out in association with a specific
data access. Similarly, there may be a need for search routines that depend on the semantics of keys or the retrieved
data. These possibilities have all been taken into consideration in the definition of a relation. A relation maps a key to a value obtained by applying the
appropriate lookup and search routines, and perhaps a postprocessing step, applied to a specified database that has a
specified access method.
The various attributes that define a relation are largely independent. There will of
course be dependencies due to the contents or other semantics of a database. In addition to the features mentioned,
each relation may optionally have associated with it a subtype, which is a string value used to tell the lookup routine
which table of several in a database one is interested in.
There are no predefined relations in the router. They must all be specified in the
configuration file before first use. This is done by calling the special function relation with various options, as indicated by the usage strings printed by the relation function when called the wrong way. See figure Figure 13-3.
The “-t” option specifies one of several
predefined database types, each with their specific lookup routine. It determines a template for the set of attributes
associated with a particular relation. The predefined database types are:
bhash-
the database is in BSD/SleepyCat DB HASH format.
bind-
the database is the BIND nameserver, accessed through the standard resolver routines.
btree-
the database is in BSD/SleepyCat DB BTREE format.
dbm-
the database is in DBM format. Note that the original dbm had no
dbm_close() function, thus there was no way to dissociate active database from a process. A bit newer variant of dbm has the close function, and multiple dbm's can be used. (You propably won't encounter this beast at all..) gdbm-
the database is in GNU GDBM format.
headers-
router internal database of various headers, and how they are to be treated.
hostsfile-
/etc/hosts lookup using
gethostbyname(). incore-
the database is a high-speed bundle of data kept entirely in the router process core memory. This is for a short-term data storage, like handling duplicate detection.
ldap-
Mechanism for X.500 Directory access lookup with the "Light-weight Directory Access Protocol."
ndbm-
the database is in NDBM (new DBM) format. (At which the length of key + length of data must not exceed 1024 bytes!)
ordered-
the database is a text file with key-datum pairs on each line, keys are looked up using a linewise binary search in the sorted file.
selfmatch-
a special type that does translate the numerical address of format 12.34.56.78 (from within address-literal bracets) into binary form, and checks that it is (or is not) actually our own local IP addresses. This is used in address literal testing of addresses of type: localpart@[12.34.56.78].
unordered-
the database is a text file with key-datum pairs on each line, keys are looked up using a sequential search. First to match is used.
yp-
Sun SunOS 4.x YP (these days "NIS") interface library.
A subtype is specified by appending it to the database type name separated by a slash, or a comma. For example,
specifying bind/mx as the argument to the “-t” option will store “mx” for reference by the access routines whenever a query to that relation is processed.
The subtypes must therefore be recognized by either the database-specific access routines (for translation into some
other form), or by the database interface itself.
For unordered and ordered database types, the datum
corresponding to a particular key may be null. This situation arises if the database is a simple list, with one key per
line and nothing else. In this situation, the use of an appropriate post-processor option (e.g. “-b”) is recommended to be able to detect whether or not the
lookup succeeded.
The “-f” option specifies the name of the
database. This is typically a path that either names the actual (and single) database file, or gives the root path for
a number of files comprising the database (e.g. “foo”
may refer to the NDBM files “foo.pag” and “foo.dir”). For the hostsfile type of
database, the /etc/hosts file is the one used (and since the normal “hosts” file access routines do not allow specifying different file, this cannot be
overridden).
The “-s” option specifies the size of the cache.
If this value is non-zero (by default it is 10), then an LRU cache of this size is maintained for previous queries to
this relation, including both positive and negative results.
The “-e” option specifies the cache data
expiration time in seconds.
The “-b” option asks that a postprocessor is
applied to the database lookup result, so the empty string is returned from the relation query if the database search
failed, and the key itself it returned if the search succeeded. In the latter case, any retrieved data is discarded.
The option letter is short for Boolean.
The “-n” option asks that a postprocessor is
applied to the database lookup result, so the key string is returned from the relation query if the database search
failed, and the retrieved datum string is returned if the search succeeded. The option letter is short for
Non-Null.
The “-l” option asks that all keys are converted
to lowercase before lookup in the database. This is mutually
exclusive with the “-u” option.
The “-u” option asks that all keys are converted
to uppercase before lookup in the database. This is mutually
exclusive with the “-l” option.
The “-d” option specifies a search routine. Most
commonly used argument for this option is “pathalias”, specifying a driver that searches for the key using domain name lookup
rules.
The “-C” option specifies a configuration file
for the underlying database mechanism. Exact details depend by the database mechanisms.
The “-%” option enables substitution of “%0” thru “%9” patterns in the db lookup results with key, iterated partial key, or positional
parameter to lookup of the database. See Reference Section 21.5.50 for
more information.
Figure 13-4. Some examples of relation definitions
relation -lmt $DBTYPE -f $MAILVAR/db/aliases$DBEXT aliases relation -lm%t $DBTYPE -f $MAILVAR/db/fqdnaliases$DBEXT fqdnaliases relation -lm%t $DBTYPE -f $MAILVAR/db/routes$DBEXT -d pathalias routes if [ -f /etc/resolv.conf ]; then relation -nt bind/cname -s 100 canon # T_CNAME canonicalize hostname relation -nt bind/uname uname # T_UNAME UUCP name relation -bt bind/mx neighbour # T_MX/T_WKS/T_A reachability relation -t bind/mp pathalias # T_MP pathalias lookup else relation -nt hostsfile -s 100 canon # canonicalize hostname relation -t unordered -f $MAILBIN/db/hosts.uucp uname relation -bt hostsfile neighbour relation -t unordered -f /dev/null pathalias fi |
Figure 13-5. More examples of alternate forms of database reference
#
# We maintain an aliases database, and may access it via NDBM,
# or via indirect indexing:
#
if [ -f $MAILBIN/db/aliases.dat ]; then
relation -t ndbm -f $MAILBIN/db/aliases aliases
else
relation -it ordered -f $MAILBIN/db/aliases.idx aliases
fi
|
Figure 13-6. More miscellaneous relation definitions to illustriate various
possibilities
relation -t unordered -f /usr/lib/news/active -b newsgroup relation -t unordered -f /usr/lib/uucp/L.sys -b ldotsys relation -t ordered -f $MAILBIN/db/hosts.transport -d pathalias transport |
The final argument for the relation is not preceeded by an option letter. It specifies
the name the relation is known under. Note that it is quite possible for different relations to use the same database
(like in case of “bind”).
Some sample relation definitions are in figure Figure 13-4. That fragment defines a set of relations that can be accessed in the same way, using the same names, independent of their actual definition.
CHECK! (-i option!) As the comment
says, the relation name aliases has special significance to the
router. Although the relation is not special in any other way (i.e. it can be used in the normal
fashion), the semantics of the data retrieved are bound by assumptions in the aliasing mechanism. (Or more
specifically, actually database compilation in case this isn't “ordered” or
“unordered” file will handle this.)
These assumptions are that key strings are local-name's, and the corresponding datum gives a byte offset into another file (the root name of the aliases file, with a “.dat” extention), which contains the actual addresses associated with that alias.
The reason for this indirection is that the number of addresses associated with a particular alias can be very large, and this makes the traditional simple database formats inadequate. For example, quick lookup in a text file is only practical if it is sorted and has a regular structure. A large number of addresses associated with an alias makes structuring a problem. The situation for DBM files and variations have problems too, due to the intrinsic limits of the storage method. The chosen indirection scheme avoids such problems without loss of efficiency.
More examples on figure Figure 13-6, where the first two illustrate convenient coincidences of format, and the last definition shows what might be used if outgoing channel information is maintained in a pathalias-format database (e.g. “bar smtp!bar” means to send mail to “bar” via the SMTP channel).
13.2.1. Using a Pathalias Database With “%0” substitution
The pathalias is an UUCP era thing, and not quite what one would need these days, but just in case…
Accessing route databases is a rather essential capability for a mailer. At the University of Toronto, all hosts access a centrally stored database through a slightly modified nameserver program. If such a setup is not practical at your site, other methods are available. The most widespread kind of route database is produced by the pathalias program.
The current ZMailer can do two separate things, which were combined into the old pathalias idea:
-
relationdefines driver routine with “-d pathalias” -
relationdefines that lookup result contained “%0” thru “%9” strings may be substituted (the “-%” option).
The pathalias generates key-value pairs of the form:
uunet ai.toronto.edu!uunet!%s .css.gov ai.toronto.edu!uunet!seismo!%s |
which need to be post-processed to:
uunet ai.toronto.edu!uunet!%0 .css.gov ai.toronto.edu!uunet!seismo!%0 |
which when queried about “uunet” and “beno.css.gov” correspond to the routes:
ai.toronto.edu!uunet ai.toronto.edu!uunet!seismo!beno.css.gov |
Notice that there are two basic forms of routes listed: routes to UUCP node names and routes to subdomain gateways. Depending on the type of route query, the value returned from a pathalias database lookup needs to be treated differently. For now, this may be accomplished by a configuration file relation definition and interface function as shown in figure Figure 13-7.
Figure 13-7. An example of lookup driver for genuine pathalias generated database
relation -t ndbm -f $MAILBIN/uuDB -d pathalias padb
# pathalias database lookup function
padblookup (name) {
local path
path = $(padb "$name")
tsift "$path" in
((.+)!)?([^!]+)!%s
if [ "$3" == "$name" ]; then
path = "$2!$3"
else
path = "$2!$3!$name"
fi
;;
.*%s.*
echo "illegal route in pathalias db: $path"
;;
tfist
return "$path"
}
|
This is actually a simplistic algorithm, but it does illustrate the method. The lookup algorithm used when the
“-d” flag is specified in the relation definition command is rather simple; it doesn't test various case combinations for the
keys it tries. Therefore, the keys in the pathalias output data should probably be converted to a single case, and
the “-l”, or “-u” option given in the relation definition as
well..
13.2.2. Mailing Lists and ~/.forward
FIXME! FIXME! -- VERIFY! UPDATE!
One form of mailing lists are implemented as files in the $MAILSHARE/lists/ directory (or symlinks in there to files residing elsewere, though from a
system reliability standpoint it is better to have them in that directory, and let users have symlinks to those files
— consider the NFS with the user home directories in other machines…)
An alternate mechanism is to implement lists in the traditional sendmail manner, however it means feeding the message to the scheduler, and external program (/usr/lib/sendmail) before it comes back to the router.
The list file must have protection 0664 or stricter, as an example: 0700 has invalid bits. (ok, so the “x”-bit is not used, but illegal it is, all the same.) Preferrable protection is: 0600
The $MAILSHARE/lists/ directory must be owned by root. The
directory containing the “aliases” file ($MAILSHARE/db/) must be owned by root, and the aliases file must comply with above mentioned
protections.
The owner of “FILE” gets “FILE-owner”, and “FILE-request” mails, unless any of the above listed limitations are breached.
If “FILE” has protection 666 (for example), the ZMailer internal function “$(filepriv $filepath)” returns “$nobody” (userid of nobody), and function “$(uid2login $nobody)” fails, thus losing “*-owner”, and “*-request” features.
Also lists with filepriv “nobody” cannot be archived simply by having an “address” of form “/file/path” amongst the recipient addresses.
This type of a mailing list is set up by creating a file in the $MAILVAR/lists/ directory. The file name is the list's name (LIST) in all lowercase (case-insensitive matching is done by converting to lowercase before
comparison).
The file contains a list of mail addresses (typically one per line) which are parsed to pull out the destination addresses. This means the users' full names can be given just as in any valid RFC822 address.
The local account which owns the file will by default receive messages sent to LIST-owner and LIST-request. This can be explicitly overridden in the aliases file. Mail to the list will go out with LIST-owner as the sender, so list bounce messages will return to the LIST-owner address. Archives of the list can be created by adding a file name address (a local pathname starting with “/”) to the LIST file. The archive file is written with the ownership of the owner of the LIST file. Forwarding the mailing list into a newsgroup can be done using a mail to news script (two generations are provided in utils/distribute and utils/mail2news in the sources).
13.2.2.1. aliases.cf Logic
FIXME! FIXME! -- VERIFY! UPDATE!
-
If an aliases database exists and local-part is found in it, the list of addresses mapped to by the alias entry is substituted.
-
If an mboxmap file exists and a mapping for the local-part is found in it, the mapping (a “host!homedir!user” value) determines the remote recipient (user@host) or recipient mailbox (homedir/../PObox/user) if host is local.
-
If local-part is a login name and a readable “~/.forward” file exists in the home directory, the list of addresses it contains is substituted.
-
If local-part is a file basename in the $
MAILVAR/lists/ directory, the list of addresses contained in the file is substituted, and the sender address set to local-part-owner. -
If local-part is of the form “file-owner” or “file-request”, where file is an entry in the $
MAILVAR/lists/ directory, the account name of the owner of the file is substituted. (File-owner identity and correct file and directory protections are important.) -
If the local-part is of format “user.name”, it is optionally mapped via separate fullnamemap.
-
If
PUNTHOSTis defined (in /etc/zmailer.conf) the address local-part@$PUNTHOST is substituted. Note that in this case the mboxmap mechanism should be used to ensure local spool mailbox delivery for local users.
13.2.2.2. aliases
FIXME! FIXME! -- aliases db regeneration methods have changed since
The file containing the actual aliasing data is automatically created by the router when asked to reconstruct the aliases database. It does this based on a text file containing the alias definitions. This text file, which corresponds to the sendmail aliases file, consists of individual alias definitions, possibly separated by blank lines or commentary. Comments are introduced by a sharp sign (octothorp: “#”) at any point where a token might start (for example the beginning of a line, but not in the middle of an address), and extend to the end of the line. Each alias definition has the exact syntax of an RFC822 message header, containing an address-list, except for comments. The header field name is the local-part being aliased to the address-list that is the header value.
The fact that an alias definition follows the syntax for an RFC822 message header, introduces an incompatibility with sendmail. The string “:include:” at the start of a local-part (a legacy of RFC733) has special semantics. Sendmail would strip this prefix, and regard the rest of the local-part as a path to a file containing a list of addresses to be included in the alias expansion. Indeed, the router behaves in the same manner, but because some of the characters in the prefix are RFC822 specials, the entire local-part must be quoted. Thus, whereas sendmail(8) allowed:
people: :include:/usr/lib/mail/lists/people |
people: ":include:/usr/lib/mail/lists/people" |
Like sendmail, if a local-part is not found in the aliases database, the router also checks “~local-part/.forward” (if such exists) for any address expansion. The .forward file format is also an RFC822 address list, similar to what sendmail expects.
As special cases, a local-part starting with a pipe character (“|”) is treated as mail destined for a program (the rest of the local-part is any valid argument to a “sh -c” command), and a local-part starting with a slash character (“/”) is treated as mail destined for the file named by the local-part.
Protection of the aliases database must be at least 0644. Protection of the $MAILVAR/db/ directory must be at least 03755, or stricter.
The following processing is done for (replacement) local-parts (local mail addresses): Note that @'s are not allowed in any local-part.
If the local-part starts with “|” assume it is a command specification:
prog-pipe: "|/path/to/program -args" |
If the local-part starts with “/” assume it is a file pathname:
file-path: "/path/to/file" |
If the local-part starts with “:include:” the rest should be a file pathname of a list of mail addresses. They are substituted:
included-list: ":include:/path/to/address/file" |
After this point, all matches are case-insensitive by means of translating the value to be looked up to
lower-case, and then conducting a case-sensitive lookup. All keys in
aliases et.al. must be in lower case — you can achieve this with bundled “newaliases” script, which calls “makedb” with “-l”
option to lowercasify keys. (The hash functions inside ndbm/gdbm/db/dbm are case sensitive, and as such, there is no way to avoid this
requirement.)
13.2.2.3. Security Considerations
A LIST file must not be world writable, while most likely it can be group-writable. The $MAILVAR/lists/ directory must also not be group or world writable and
must be owned by root or by the owner of the LIST file. Otherwise the file is declared insecure and all addresses
in the file get the least possible privilege associated (the “nobody” uid).
This can cause various things to break, for example mailing list archival, or the -owner and -request features if
“nobody” is not a valid account.
There is a mechanism to override using the modes on a file/directory as an indicator of its safeness.
Turning on the sticky bit on a file or directory tells the mailer to treat it as if it was only owner writable independent of its actual modes.
This allows $MAILVAR/lists/ to be group or world writable
and sticky-bitted if you want your general user population (or special admin group) to be able to create mailing
lists.
Chapter 14. Scheduler Administration
- Table of Contents
- 14.1. Principiles of scheduling: Threads
- 14.2. Scheduler Resource Control
- 14.3. The scheduler.conf file
- 14.4. Scheduler's Mailq
- 14.5. Scheduler's scheduler.auth control file
- 14.6. manual-expirer
- 14.7. Scheduler's Diagnostics Reporting
The scheduler is the part of the ZMailer that manages message processing outbound from the MTA proper.
The Figure 14-1 repeats earlier picture showing central components of the system, and where the scheduler is in relation to them all.
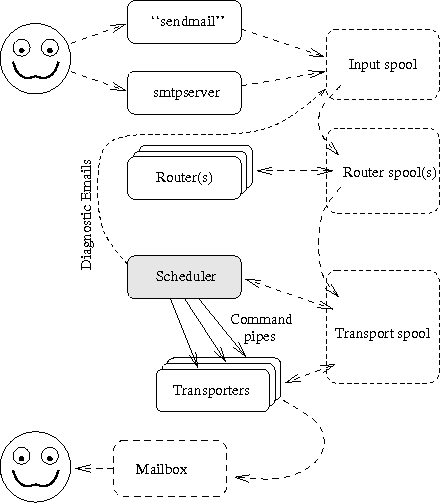
TODO!FIXME!
Here we present longer examples out of the scheduler.conf, and
reasons why the default script is as it is
- Intro
- Principles of scheduling, "threads"
- Clause selectors
- "local/*"
- "smtp/*.xyz"
- "smtp/*"
- "OTHER/*"
- How to roll your own when needed
- Something about the resource control ?
- scheduler.auth file, and its purpose
- MAILQv1/v2 interface, mailq-command
- but the protocols are REFERENCE material
- (manual-)expirer
- Diagnostics reporting, forms files
Appendix B contains full samples of scheduler.conf, and scheduler.auth
|
The major action of the scheduler is to periodically start up Transport Agents and tell them what to do. This is controlled by a table in a configuration file that is read by the scheduler when it starts.
The scheduler receives the messages from the router in two files: Original message file in $POSTOFFICE/queue/, and router written transport-specifications in $POSTOFFICE/transport/.
Because usually (UNIX) systems don't like of having very large amounts of files in directories, as lookups for them
become intolerably slow, the scheduler has a subdirectory hashing mechanism. Both queue/ and transport/ can be
split to subdirectories at one or two levels with names of “A” thru “Z”. See for the
“-H” option of the scheduler
below.
The idea with the sub-directory hashes is to split the workset into as even subsets as possible, usually busy systems
are run with “-HH” to have 26*26 sub-sub-directories
into which the sets gets divided.
14.1. Principiles of scheduling: Threads
The router produces recipients “address quads” which consists of four components:
-
Channel
-
Host
-
User
-
Privilege
Of these, Channel, and Host parts are used by the scheduler to classify message recipients and to choose to what Transport Agents to use, and how to use them.
To control how messages are sent out, the scheduler uses catenation of: Channel/Host to group recipients. All recipients with same values there are groupped together in what is called thread.
Another related thing is so called thread group, which is the collection of all threads within same scheduler Selector Clause. See Section 14.3.
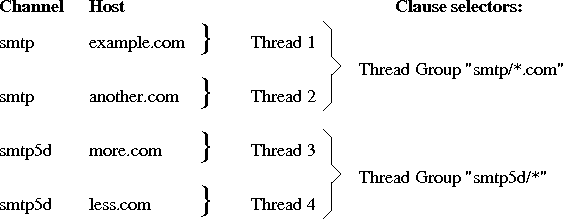
In normal case the scheduling is done by running single transport agent for the thread, which delivers messages one at the time. This means that a single destination with thousands of messages does not block the system significantly more than some other destination with a single message.
Also in normal cases, when messages in given thread are all delivered, or otherwise determined that nothing can be done, the transport agent can be switched to another thread within the same thread group.
14.2. Scheduler Resource Control
FIXME! TO BE WRITTEN!
Note, there are three kinds of resource-pool limitation parameters which control when a given channel+host pair (thread) is NOT taken into processing:
- MaxTA: (Set in “*/*” clause)
-
GLOBAL parameter limiting the number of transport-agent processes that the scheduler can have running at the same time.
With this you can limit the number of TA processes running at the same time lower than maximum allowed by your OS setup.
The scheduler detects the max number of FDs allowed for a process, and analyzing how many FDs each TA interface will need -- plus reserving 10 FDs for the itself, result is “probed maxkids”.
- MaxChannel: (default: “probed maxkids”)
-
Selector clause specific value limiting how many transport-agent processes can be running on which the “channel” part is the same. You may specify dis-similar values for these as well. For example you may use value '50' for all your 'smtp' channel entries, except that you want always to guarantee at least five more for your own domain deliveries, and thus have:
smtp/*your.domain maxchannel=55If the sum of all “maxchannel” values in different channels exceeds that of “maxta”, then “maxta” value will limit the amount of work done in extreme load situations.
- MaxRing: (default: “probed maxkids”)
-
This limits the number of parallel transport agents within each selector definition. This defined the size of the POOL of transport agent processes available for processing the threads matching the selector clause.
- MaxTHR: (default: 1)
-
This limits the number of parallel transport agents within each thread; that is, using higher value than default “1” will allow running more than one TA for the jobs at the thread.
Do note that running more than one TA in parallel may also require lowering OVERFEED value. (E.g. having a queue of 30 messages will not benefit from more TAs, unless they all get something to process. Having OVERFEED per default at 150 will essentially feed whole queue to one TA, others are not getting any.)
- OverFeed:
-
This tells how many job specifiers to feed to the TA when the TA process state is “STUFFING” Because the scheduler is a bit sluggish to spin around to spot active TAs, it does make sense to feed more than one task to a TA, and then wait for the results.
14.3. The scheduler.conf file
Any line starting with a “#” character is assumed to be a comment line, and is ignored, as are empty lines. All other lines must follow a rigid format.
The scheduler configuration file consists of a set of clauses. Each clause is selected by the pattern it starts with. The patterns for the clauses are matched, in sequence, with the channel/host string for each recipient address. When a clause pattern matches an address, the parameters set in the clause will be applied to the scheduler's processing of that address. If the clause specifies a command, the clause pattern matching sequence is terminated. Example of the clause can be seen in figure Figure 14-3.
Figure 14-3. Example of scheduler.conf clause
local/*
interval=10s
expiry=3h
# want 20 channel slots in case of blockage on one
maxchannel=20
# want 20 thread-ring slots
maxring=20
command="mailbox -8"
|
A clause consists of:
-
A selection pattern (in shell style) that is matched against the channel/host string for an address.
-
0 or more variable assignments or keywords (described below).
If the selection pattern does not contain a '/', it is assumed to be a channel pattern and the host pattern is assumed to be the wildcard '*'.
The components of a clause are separated by whitespace. The pattern introducing a clause must start in the first column of a line, and the variable assignments or keywords inside a clause must not start in the first column of a line. This means a clause may be written both compactly all on one line, or spread out with an assignment or keyword per line.
If the clause is empty (i.e., consists only of a pattern), then the contents of the next non-empty clause will be used.
The typical configuration file will contain the following clauses:
-
a clause matching all addresses (using the pattern */*) that sets up default values.
-
a clause matching the local delivery channel (usually local).
-
a clause matching the deferred delivery channel (usually hold).
-
a clause matching the error reporting channel (usually error).
-
clauses specific to the other channels known by the router, for example: smtp and uucp.
The actual names of these channels are completely controlled by the router configuration file.
Empty lines, and lines whose first non-whitespace character is “#”, are ignored.
Variable values may be unquoted words or values or double quoted strings. Intervals (delta time) are specified using a concatenation of numbers suffixed with 's', 'm', 'h', or 'd'; modifiers designating the number as a second, minute, hour, or day value. For example: 1h5m20s.
The known variables and keywords, and their typical values and semantics are:
interval(1m)-
specifies the primary retry interval, which determines how frequently a transport agent should be scheduled for an address. The value is a delta time specification. This value, and the retries value mentioned below, are combined to determine the interval between each retry attempt.
idlemax-
When a transport agent runs out of jobs, they are moved to “idle pool”, and if a transport agent spends more than idlemax time in there, it is terminated.
expiry(3d)-
specifies the maximum age of an address in the scheduler queue before a repeatedly deferred address is bounced with an expiration error. The actual report is produced when all addresses have been processed.
retries(1 1 2 3 5 8 13 21 34)-
specifies the retry interval policy of the scheduler for an address. The value must be a sequence of positive integers, these being multiples of the primary interval before a retry is scheduled. The scheduler starts by going through the sequence as an address is repeatedly deferred. When the end of the sequence is reached, the scheduler will jump into the sequence at a random spot and continue towards the end. This allows various retry strategies to be specified easily:
- brute force (or “jackhammer”)
-
retries=0
- constant primary interval
-
retries=1
- instant backoff
-
retries="1 50 50 50 50 50 50 50 50 50 50 50 50"
- slow increasing (fibonacci) sequence
-
retries="1 1 2 3 5 8 13 21 34"
- s-curve sequence
-
etries="1 1 2 3 5 10 20 25 28 29 30"
- exponential sequence
-
retries="1 2 4 8 16 32 64 128 256"
maxta(0)-
FIXME: REVISE RESOURCE CHECK NOTES! if retrying an address would cause the number of simultaneously active transport agents to exceed the specified value, the retry is postponed. The check is repeated frequently so the address may be retried as soon as possible after the scheduled retry interval. If the value is 0, a value of 1000 is used instead. Keep in mind that all running transport agents will keep open two
pipe(2) file-handles, (or onesocketpair(2), if system has such bidirectional pipe entity,) and thus system-wide limits may force a lower maximum than 1000. On a system with a maximum of 256 open files, this would most likely succeed at 120. maxchannel(0)-
if retrying an address would cause the number of simultaneously active transport agents processing mail for the same channel to exceed the specified value, the retry is postponed. The check is repeated frequently so the address may be retried as soon as possible after the scheduled retry interval. If the value is 0, a value of 1000 is used instead.
maxring(0)-
Recipients are groupped into “threads”, and similar threads are groupped into “thread-rings”, where the same transport agent can be switched over from one recipient to another. This defines how many transport agents can be running at any time at the ring.
skew(5)-
is the maximum number of retries before the retry time is aligned to a standard boundary (seconds since epoch, modulo primary interval). The lower this number (1 is lowest), the faster the alignment is done. The purpose of this alignment is to ensure that eventually a single transport agent invokation will be able to process destination addresses that arrived randomly at the scheduler.
user(root)-
is the user id of a transport agent processing the address. The value is either numeric (a uid) or an account name.
group(daemon)-
is the group id of a transport agent processing the address. The value is either numeric (a gid) or a group name.
command(smtp -srl ${LOGDIR}/smtp ${host}-
is the command line used to start a transport agent to process the address. The program pathname is specified relative to the $
MAILBIN/ta/ directory. The string “${channel}” is replaced by the current matched channel, and “${host}” is replaced by the current matched host, from the destination address, and “${LOGDIR}” substitutes ZENV variableLOGDIRvalue there.It is strongly recommended that the “${host}” is not to be used on command definition, as it limits the recyclability of the idled transporter.
bychannel-
is a keyword (with no associated value which tells the scheduler that the transport agent specified in the command will only process destination addresses that match the first destination channel it encounters.
This is automatically set when the string “${channel}” occurs in the command, but may also be specified manually. This is rarely used.
queueonly-
a clause with queueonly flag does not auto-start at the arrival of a message, instead it must be started by means of smtpserver(8) command ETRN thru an SMTP connection.
An example of full scheduler.conf file is in figure Figure 14-4.
Figure 14-4. Example of full scheduler.conf file
# Default values
*/* interval=1m expiry=3d retries="1 1 2 3 5 8 13 21 34"
maxring=0 maxta=0 skew=5 user=root group=daemon
# Boilerplate parameters for local delivery and service channels
local/* interval=10s expiry=3h maxchannel=2 command=mailbox
error interval=5m maxchannel=10 command=errormail
hold/* interval=5m maxchannel=1 command=hold
# Miscellaneous channels supported by router configuration
smtp/*.toronto.edu
smtp/*.utoronto.ca maxchannel=10 maxring=2
command="smtp -srl ${LOGDIR}/smtp"
smtp maxchannel=10 maxring=5
command="smtp -esrl ${LOGDIR}/smtp"
uucp/* maxchannel=5 command="sm -c ${channel} uucp"
|
The first clause (*/*) sets up default values for all addresses. There is no command specification, so clause matching will continue after address have picked up the parameters set here.
The third clause (error) has an implicit host wildcard of “*”, so it would match the same as specifying error/* would have.
The fifth clause (smtp/*.toronto.edu) has no further components so it selects the components of the following nonempty clause (the sixth).
Both the fifth and sixth clauses are specific to address destinations within the TORONTO.EDU and UTORONTO.CA organization (the two are parallel domains). At most 10 deliveries to the smtp channel may be concurrently active, and at most 2 for all possible hosts within TORONTO.EDU. If “$host” is mentioned in the command specification, the transport agent will only be told about the message control files that indicate SMTP delivery to a particular host. The actual host is picked at random from the current choices, to avoid systematic errors leading to a deadlock of any queue.
14.4. Scheduler's Mailq
FIXME! TO BE WRITTEN!
14.5. Scheduler's scheduler.auth control file
FIXME! TO BE WRITTEN!
14.6. manual-expirer
FIXME! TO BE WRITTEN!
14.7. Scheduler's Diagnostics Reporting
FIXME! TO BE WRITTEN!
14.7.1. Scheduler's Diagnostics Reporting, Forms Files
FIXME! TO BE WRITTEN!
Chapter 15. Transport Agent Administration
- Move to be a SECTION of Scheduler ? - These are support thingies for the Scheduler anyway. - Less details than REFERENCE has, focus differently - sm - smtp - mailbox - hold - expirer - errormail |
These are ZMailer's components driven by the Scheduler to actually do message delivery actions.
The Figure 15-1 repeats earlier picture showing central components of the system, and where the transport agents are in relation to the whole.
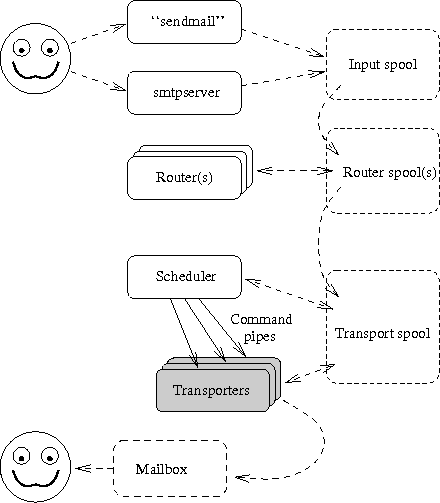
15.1. Sm Transport Agent
sm is a ZMailer's sendmail(8) compatible transport agent to deliver messages by invoking a program with facilities and in a way compatible with a sendmail(8) MTA.
The program scans the message control files named on stdin for addresses destined for the channel and/or the host given on the command line. If any are found, all matching addresses and messages are processed according to the specifications for the mailer in the configuration file.
The exit status of a mailer should be one of the standard values specified in #include <sysexits.h>. Of these, EX_OK indicates successful deliver, and EX_DATAERR, EX_NOUSER, EX_NOHOST, EX_UNAVAILABLE, and EX_NOPERM indicate permanent failure. All other exit codes will be treated as a temporary failure and the delivery will be retried.
Usage:
sm [-8] [-H] [-Q] [-V] [-f configfile] -c channel -h host mailer
Configuration:
The configuration file $MAILSHARE/sm.conf associates the
mailer keyword from the command line with a specification of a delivery program. This is very similar to the way the
definition of a “mailer” in sendmail(8). It requires
flags, a program name, and a command line specification. These are in fact the fields of the entries of the
configuration file. Lines starting with whitespace or a “#” are ignored, and all others are assumed to follow format shown in figure Figure 15-2.
Figure 15-2. Sample sm.conf file
#mailer flags program argument list #====== ===== ============== ================================ local mS sm/localm localm -r $g $u prog - /bin/sh sh -c $u tty rs /usr/local/to to $u uucp U /usr/bin/uux uux - -r -a$g -gC $h!rmail ($u) usenet m sm/usenet usenet $u test n sm/test test $u |
The mailer field extends from the beginning of the line to the first whitespace. It is used simply as a key index to the configuration file contents. One or more whitespace is used as the field separator for all the fields.
The flags field contains a concatenation of one-letter flags. If no flags are desired, a “-” character should be used to indicate presence of the field. All normal sendmail (of 8.11(.0)) flags are recognized, but the ones that do not make sense in the context of ZMailer will produce an error (or some are ignored). The flags that change the behaviour of sm are:
b-
will activate BSMTP-type wrapping with a “hidden-dot” algorithm; e.g. quite ordinary SMTP stream, but in “batch mode”.
B-
The first “
B” turns on similar BSMTP wrapping as “b”, but adds SIZE and, if the sm is started with option “-8”, also 8BITMIME options. The second “B” adds there also DSN (Delivery Status Notification) parameters. E-
will prepend “
>” to any message body line starting with “From ”. (Read: “From-space”) f-
adds “
-f sender” arguments to the delivery program. n-
will not prepend a “From ”-line (normal mailbox separator line) to the message.
r-
adds “
-r sender” arguments to the delivery program. S-
will run the delivery program with the same real and effective uid as the sm process. If this flag is not set, the delivery program will be run with the real uid of the sm process. This may be useful if sm is setuid.
m-
informs sm that each instance of the delivery program can deliver to many destinations. This affects
$uexpansion in the argument list, see below. P-
prepends a “Return-Path:” header to the message.
U-
will prepend a “From ”-line, with a “remote from myuucpname” at the end, to the message. This is what is expected by remote rmail(1) programs for incoming UUCP mail.
R-
use CRLF sequence as end-of-line sequence. Without it, will use LF-only end-of-line sequence.
X-
does SMTP-like “hidden-dot” algorithm of doubling all dots that are at the start of the line.
7-
will strip (set to 0) the 8th bit of every character in the message.
The path field specifies the location of the delivery program. Relative pathnames are allowed and are relative to
the $MAILBIN/ directory.
The arguments field extends to the end of the line. It contains whitespace separated argv parameters which may contain one of the following sequences:
$g-
which is replaced by the sender address.
$h-
which is replaced by the destination host.
$u-
which is replaced by the recipient address. If the “
m” mailer flag is set and there are several recipients for this message, the argument containing the “$u” will be replicated as necessary for each recipient.